The Rise of Context Engineering
The 2 stages: Gather and Glean

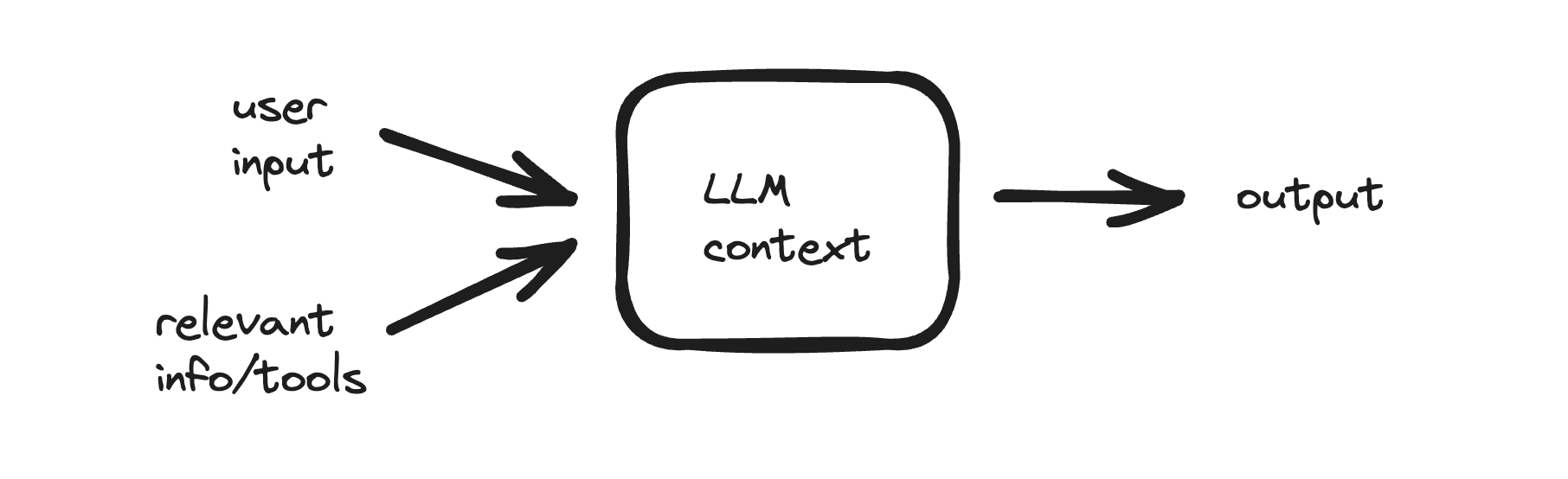
Context engineering is a far better term than prompt engineering or RAG. Prompt engineering typically refers to fiddling with the system instructions and RAG has lost all meaning entirely. Context engineering clearly describes the job to be done - engineers building effective LLM systems must optimize the information in the context window for the best accuracy and reliability.
Chroma’s recent technical report on Context Rot demonstrated that longer context:
weakens the model's ability to find relevant information
degrades reasoning capabilities
Context engineering therefore is incredibly important to build reliable production AI systems today.
Broadly speaking the goal of context engineering is to:
find relevant information
remove irrelevant information
optimize relevant information
Which information?
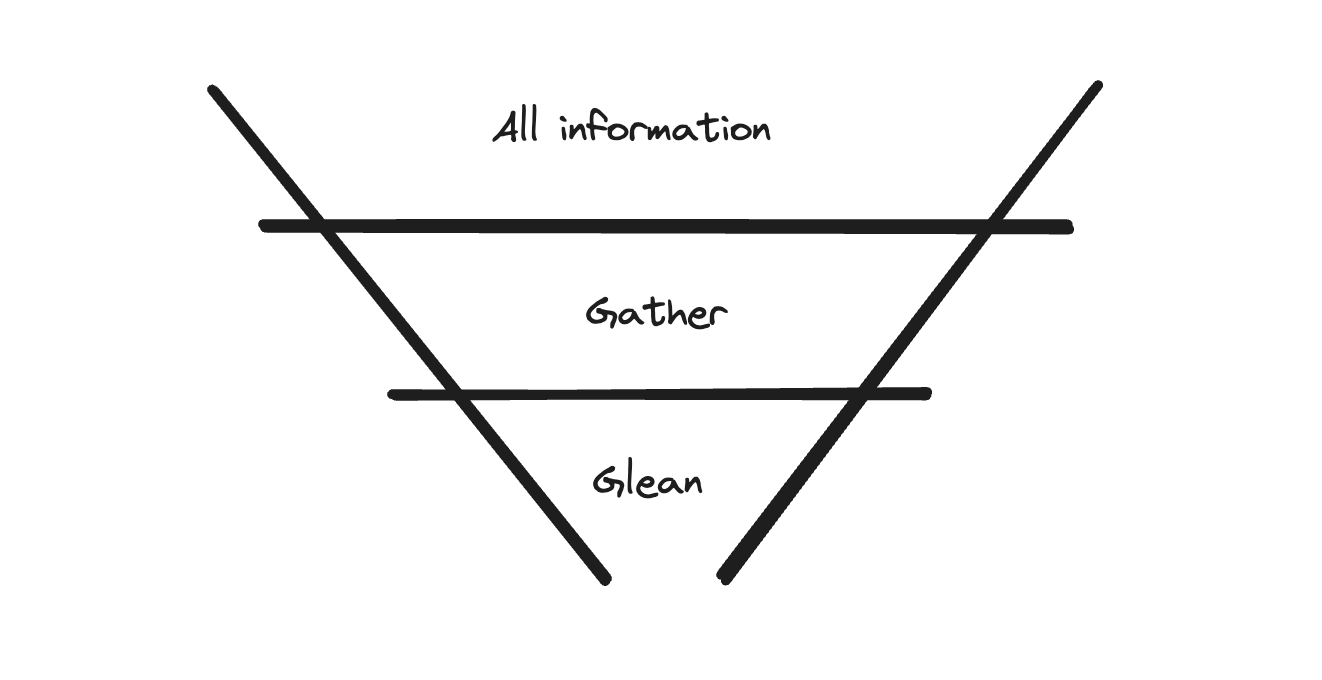
"Of all possible information in the universe, which information should be in the context window?"
We need to go from a universe of information, to only the information that should be in the context window. The goal is to find high-signal relevant information for a given query.
Relevance is a tricky subject and is often highly domain specific. In code search - relevance might include the files you currently have open. In a browser, the assumption that current open tabs are relevant may not hold.
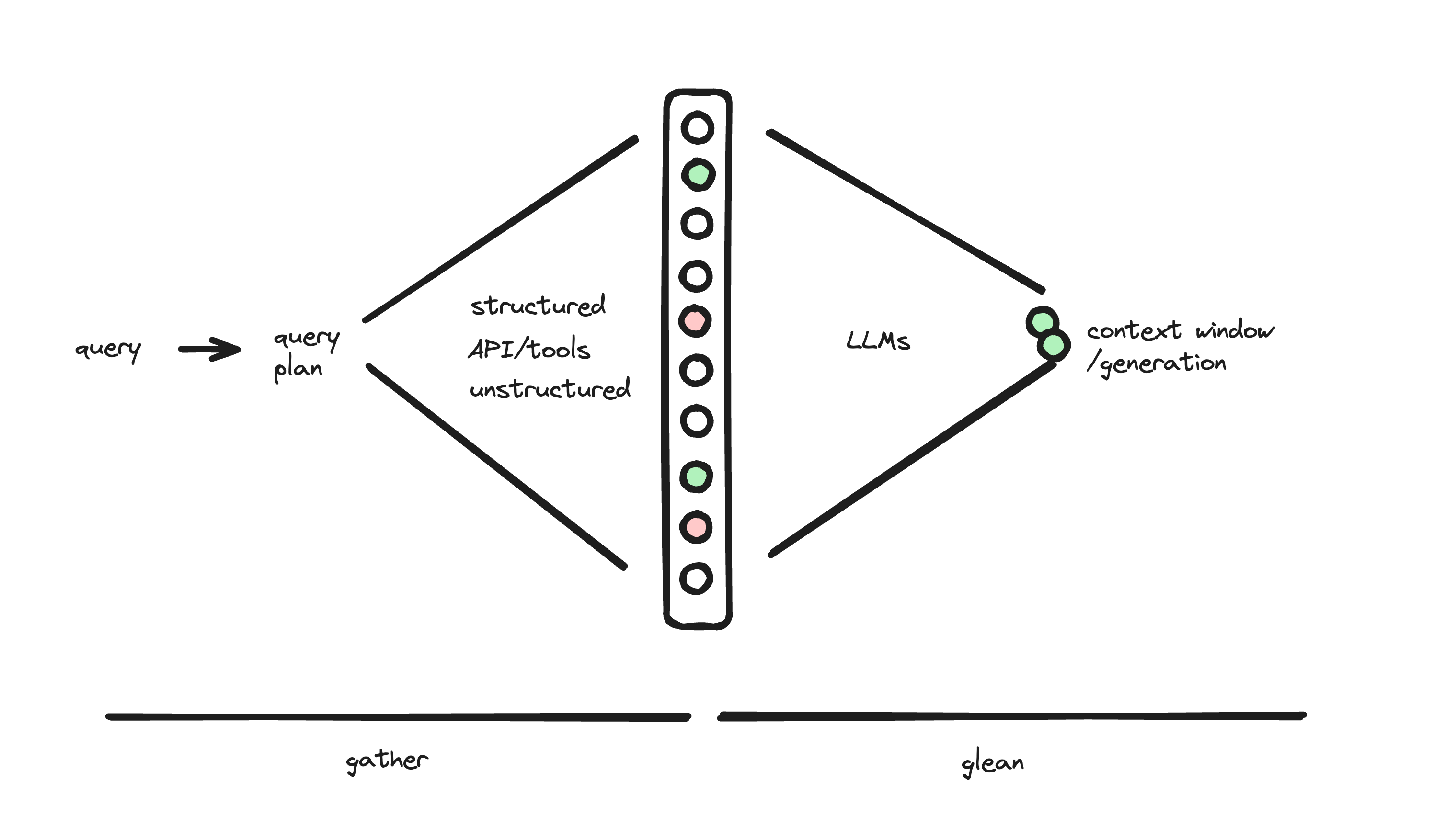
Selecting information is a 2 stage process.
Gather: the goal of this stage is to cast a wide net and find all-possible relevant information. This also means that you will also grab irrelevant information. Search is a common tool here. You can also think about this as maximizing recall.
Glean: the goal of this stage is to remove all irrelevant information such that only the relevant information is left. Reranking is a common tool here. You can also think about this as maximizing precision.
Gather
As a developer - you'll want to think about:
what kinds of inputs you want to support / what inputs your users are submitting
which information are required to answer those queries / complete those tasks
what signal will connect that query to those information
The number and type of data sources can vary - but broadly they fall into these buckets.
structured data (eg data in a relational database)
unstructured data (eg data in Chroma)
local filesystem tools (eg open tabs for code search)
tools (eg API/MCP tools, web search)
chat conversation history (simple chat apps might be only this)
For many applications, here are some common signals to determine relevance:
semantic similarity as determined by an embedding
lexical similarity as determined by full-text matches
metadata similarity as determined by metadata matches (eg WHERE clauses)
Indexing vs Brute force for Search
If you have small data - you might be able to use an LLM to manually brute force it. For example: if you want to query/process a single page of content - you probably don't need to build an index.
Indexing is an optimization that trades write-time performance for query-time performance. Indexing bends the curve of linearly increasing cost and latency relative to data scale.
Indexing can make all systems faster and cheaper to run. Where this line is for your current and planned scale you will have to decide.
Glean
Now that you have a pool of candidate information - the next task is to cull it down to the minimal set of highly relevant information specific to this task.
For some use cases - a simple slicing off of the top 10 most semantically-similar chunks works well. But most production context engineering pipelines take additional signals into account.
There are many strategies people employ to rank and cull information:
Single vector search top-k
Reciprocal Rank Fusion (RRF) is simple algorithm that assigns points for being in vector search results and full-text search results
Learning-to-rank (LTR) is often a small ML model (eg XGBoost) that is trained on numeric features like page views, clicks, etc
Reranker models focus on the job of ranking chunks according to textual relevance (pointwise, pairwise, and listwise are different strategies)
Increasing developers are using LLMs themselves to do many types of ranking and relevance detection.
We are seeing more and more developers use LLMs directly. Other strategies are more bleeding edge include dynamic chunk rewriting, token masking and more. Best practices are still emerging!
Measuring and improving your system
Today there is no magic bullet and that is good for teams who are smart and move fast. Context engineering is where strong differentiation happens. The reason you love one AI tool and dislike a similar AI tool is likely because of the context engineering the developers have put into the product. In a MVC CRUD app your business logic is encoded in controllers, in an AI app your business logic is encoded in context.
Conjoined circles of success
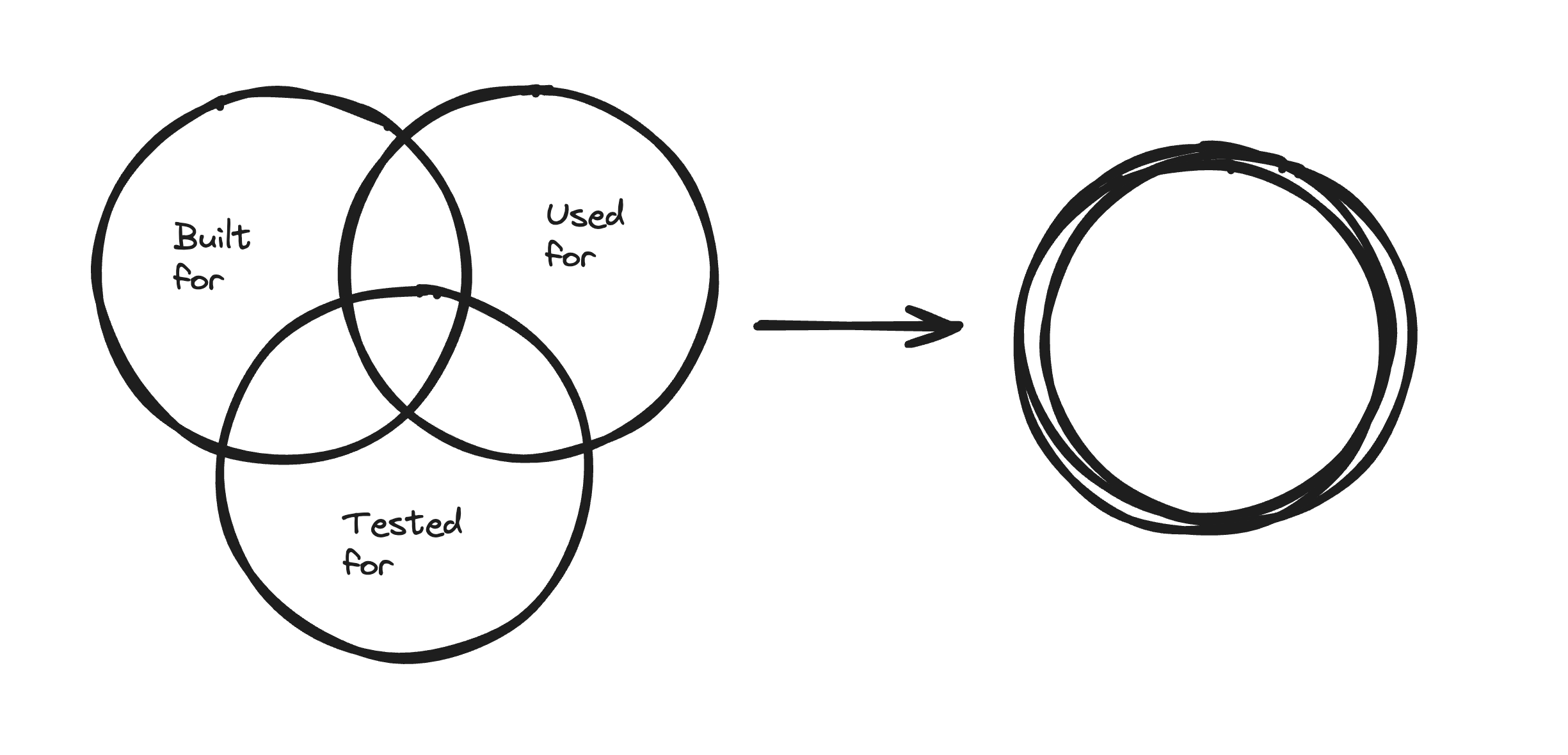
Many developers are still frustrated by how much of a dark art this all seems, but it’s much simpler than it appears. The goal is to decrease the gaps between:
what you built your system to do
what users want it to do
what you can test your system does well
The most powerful tool in your arsenal is a golden dataset. (Or “test cases” with less jargon)
A golden dataset is as simple as a big spreadsheet with 2 columns:
if this query - then this information
this that query - then that information
...............
For example, here is a query-document pair from the MTEB dataset commonly used in retrieval benchmarking.

Chroma demonstrated in our research on Generative Benchmarking how you can easily generate custom golden datasets from your own data
While golden datasets are not perfect - they have a very powerful property: it now becomes trivial to test if changes impact performance.
Which embedding model/reranker works best on my data?
How does chunking strategy impact my score?
Does chunk rewriting/document cleaning improve my scores at all?
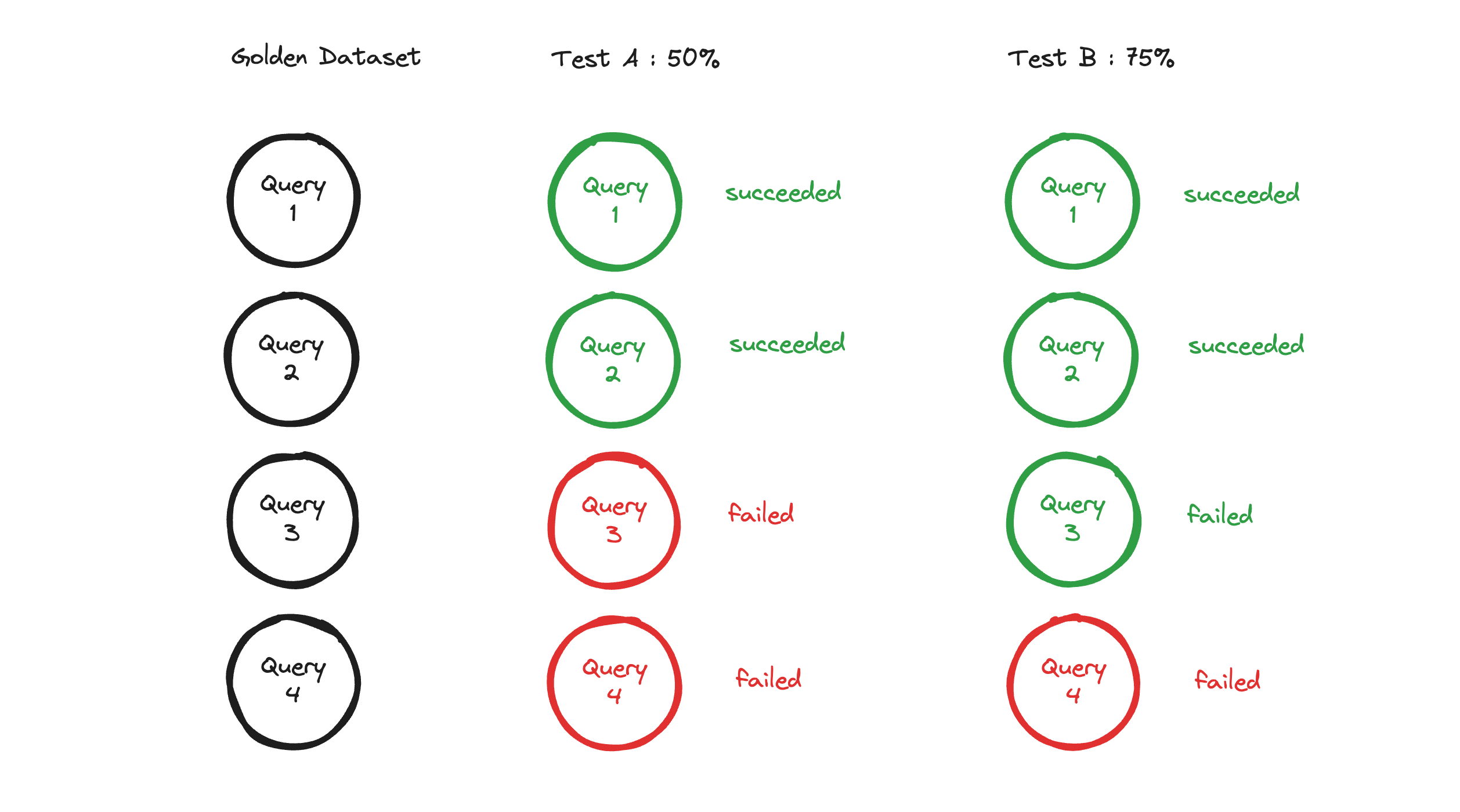
For example - perhaps you change your embedding model from A to B - you now know your application is 15% better!
Version A -> run through golden dataset -> 72% of relevant information found
Version B -> run through golden dataset -> 87% of relevant information found
Improvement in accuracy should be considered in the larger picture of engineering decisions like cost, speed, reliability, security and privacy. Instead of guessing - you can now systematically improve.
Golden datasets seem difficult to make - but they are quite easy. Get your whole team to work late and buy a few pizzas. (in fact: if you are using Chroma we will buy you pizza → DM me) Spend a few hours writing these query-information pairs for all the different use cases you can think of. Congrats, you’ve bootstrapped your golden dataset!
When your application is in production - you can improve your golden dataset by studying what your users are doing in production. Through analyzing user queries and whether they succeeded or failed - you can continue to battle-harden your golden dataset.
Today closing this loop is a manual process. In fact, it’s just the classic loop of software development.
Build
Test
Deploy
Monitor
Iterate
The best products have the best context
There is a lot of fear, uncertainty, and doubt about whether the model layer will eat the application layer, whether the application layer will eat the model layer, and where differentiation and stickiness lies.
We believe that the best AI experiences come from the teams that spend the most time on context engineering. This requires
user research: studying in detail what users are using your application for and how you can better serve those use cases (reduce failure modes) and expand the use cases you serve
better data and better weights: getting access and/or building unique datasets enable you to bring more relevant information to the context window and teach models how to process that kind information
feedback-driven-development: being obsessed about systematically improving your context engineering system through empirical signal and feedback resulting in continual improvement
To build the best product - you must talk to users and engineer context.
We all have the same goal - we want to build AI systems that learn and adapt, that can get better over-time through improving their knowledge, changing their prompts, and adjusting their weights.
There are emerging techniques to do automatic and continual improvement of context from feedback. We are hosting a private invite-only event in SF In September on this - if you’d like to attend please apply.
Stay hungry, stay foolish.

Thanks to Nick Khami, Drew Breunig, and the Chroma team for reviewing drafts of this post.